基本概念
节点 :一个elasticsearch进程,节点分datanode(数据节点),masternode(管控节点),ingestnode(接入节点)三种。1个进程可以同时担任这3个角色。
索引库 :Index,document数据以及倒排索引的合集。
- 类型 :Type,索引中一部分文档的逻辑分类,可以强行理解为关系数据库的一个表,但事实上差距蛮大的,它的本质是一个可搜索字段。6.0后一个索引下只允许有一个类型,es7据说要删除掉Type。
- 文档 :Document,一行具体的文档,es以document为单位来存储和操作数据。
- shard :分片,一个索引被切成若干个分片。一个单独的分片是一个lucence索引库
- segment :分段,分段属于lucence索引库,一个es的shard可以看做一个独立的lucence。
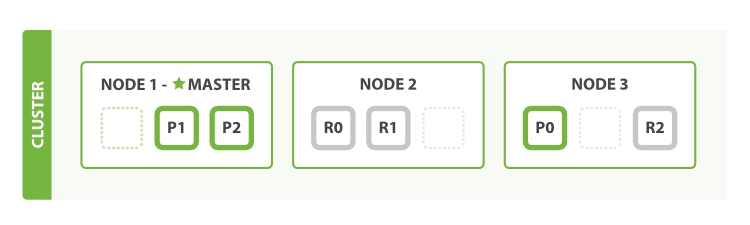
如上图所示。NODE1,NODE2,NODE3为节点;P0、P1、P2为主分片,R0、R1、R2为副分片,这6个分片组成一个索引库,存储在索引库中的数据为document。
es架构
节点类型
只有被标志为可以成为master(默认都是可以为master)的节点才会参与选主。es的选主方式很简单,在加入集群的时候如果发现没有master,就会自己申请成为master,节点在初始化的时候有一个节点uuid,根据这个uuid做字典序,排第一的候选者成为master。
- master node :负责维护元数据,管理集群状态。往其他节点发送event事件。包括创建分片,重分配分片,merge分段等等等等。master节点是很重要但是又对资源没啥要求的节点,所以最好分出来部署。以免出现灵异事件火星撞地球什么的,导致master节点宕机。
- data node: 具体存储数据和查询数据的人。开销最大。
- ingest node:一般叫client node,不存储数据也不做管控作用,相当于集群的代理层,接受外部请求转发给集群。现在的集群也是有3台client node在集群中,nginx对应的url就是转发给client node,在当前集群只有3台的时候没什么用。等节点更多的时候就有用了。
集群扩容
正常情况下,为了防止集群脑裂和服务的高可靠,需要3个节点起。看看集群在不同节点数下的演变。
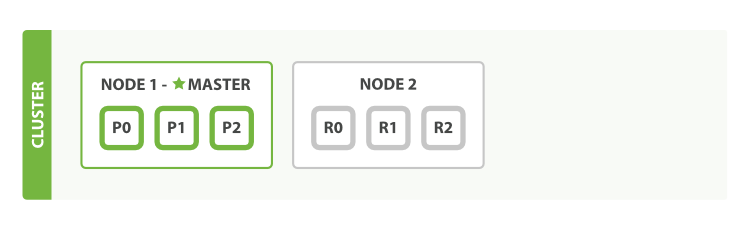
单节点

所有分片落在同一台机器上,没有副本,这种情况下,只要机器一挂,数据就没了。添加ha
可以给索引增加一个副本。当其中一个节点挂了的时候,还可以继续使用。副本分片也是可以直接用于查询的,但是不能用于写入。当主分片挂了后,副本分片会自动变主分片。看上去是有ha了,但这个时候集群容易发生脑裂问题。防脑裂/动态扩容
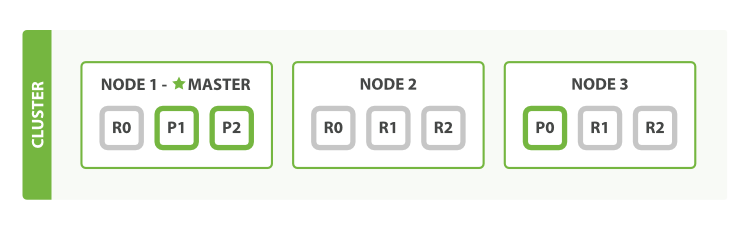
再增加一个节点,集群变成了3个节点。刚加进来的第3个节点是空的,集群会做动态的负载均衡,自动把分片数据迁移到新加入的节点。如果对数据可靠性要求很高的话,可以把副本数变成2个,让数据以三副本的方式存在,不过单副本和副本丢失后自动恢复的功能,让单副本满足了大多数的场景。- 三副本增加数据可靠性
动态修改副本数,集群自动生成副本分片 - 出现故障后自动迁移
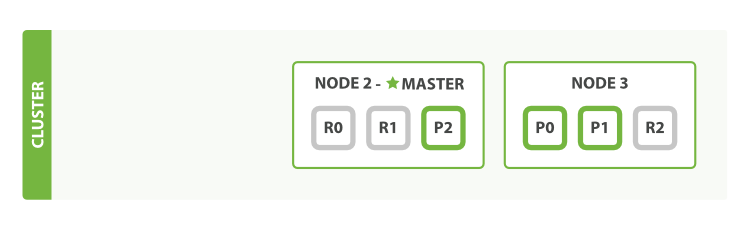
当node1宕机后,副本分片会变成主分片,并自动生成node1上对应的丢失的分片.
对文档的具体操作
- 创建、更新、删除一个文档
 。客户端只会收到一次成功的请求,文档会在主分片和副本分片上都发生更改。可以在请求的时候带上consistency参数,默认是一半的副本数+1,当写入足够多的时候就会返回。 更新和删除和创建略有不同,更新和删除的实际操作是把新版本的数据放在一个新的segment中,把旧的版本的数据放在一个被描述为删除的合集(.del文件)中,而被删除的数据也是可以被索引到的,只是在返回给客户端前过滤掉了。
。客户端只会收到一次成功的请求,文档会在主分片和副本分片上都发生更改。可以在请求的时候带上consistency参数,默认是一半的副本数+1,当写入足够多的时候就会返回。 更新和删除和创建略有不同,更新和删除的实际操作是把新版本的数据放在一个新的segment中,把旧的版本的数据放在一个被描述为删除的合集(.del文件)中,而被删除的数据也是可以被索引到的,只是在返回给客户端前过滤掉了。
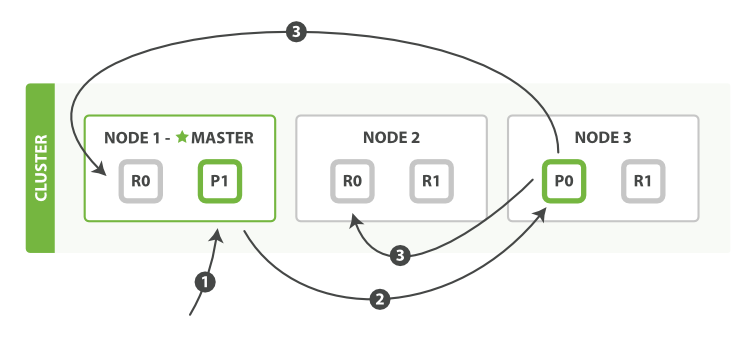
主要步骤:- 客户端连接上node1,做了一次数据变更请求(index,create,delete)。
- node1发现对应的请求数据(默认按id路由)在分片node3的p0上。将请求forwards到node3。
- node3执行p0的数据操作,并在p0操作成功后,把请求发送给副本所在的node1的R0和node2的R0.所有副本分片都操作成功后,node3给node1报告操作成功。
- 客户端连接上node1,做了一次数据变更请求(index,create,delete)。
- **分布式搜索**
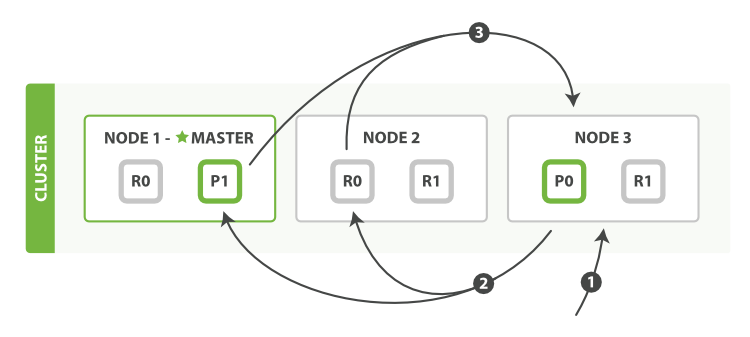
1. 客户端发送一个 search 请求到 Node 3 , Node 3 会创建一个大小为 from + size 的空优先队列。
2. Node 3 将查询请求转发到索引的每个主分片或副本分片中。每个分片在本地执行查询并添加结果到大小为 from + size 的本地有序优先队列中。
3. 每个分片返回各自优先队列中所有文档的 ID 和排序值给协调节点Node3 ,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表
- **获取文档**
获取文档,不像数据变更动作,可以从副本上获取具体文档。在索引正在生成的情况下,由于流言最终一致性协议原因,有可能出现主分片索引建立好了,能查询到,但是副本分片还未建立好索引,查询不到的情况。
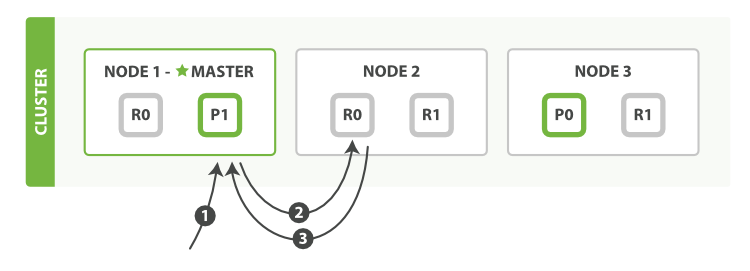
主要步骤:
1. node1接受到获取文档的请求。根据id得知文档在分片0上。
2. 分片0在node3上有一个主分片p0,在node1和node2上有两个副本分片R0.随便找一个副本分片获取。
### 分片内部原理
一个分片可以看做是一个完整的lucence索引。一个lucence索引有多个分段。每个分段都是不可变的。因此,高频update的业务并不适合es。
#### 插入数据的具体动作
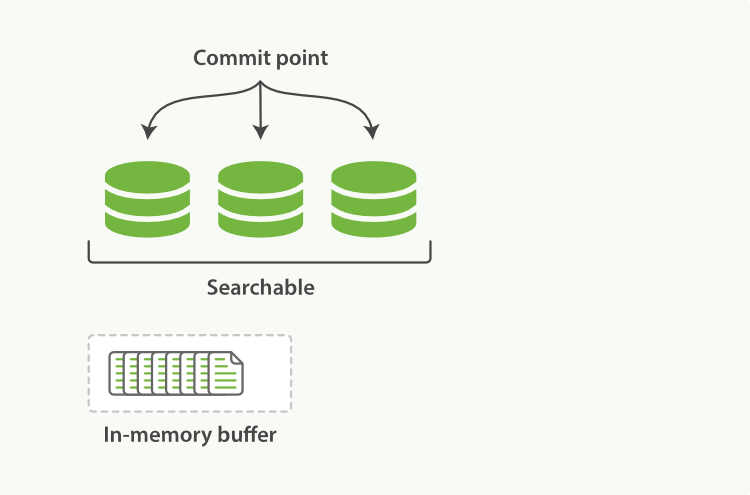
如上图所示,一个完整的lucence索引包含3个segment以及内存中的数据in-memory buffer。内存中的数据此时还不可查询。
- **新增的数据**:
新增一个文档的大致可以认为有三步。数据进入内存->数据进入文件系统缓存->数据flush到硬盘。lucence按分段搜索,但一整个segment flush到硬盘,是个开销比较大的动作。因此,数据在到文件系统缓存的时候,就让数据可以被搜索。
- **refresh到文件系统缓存**
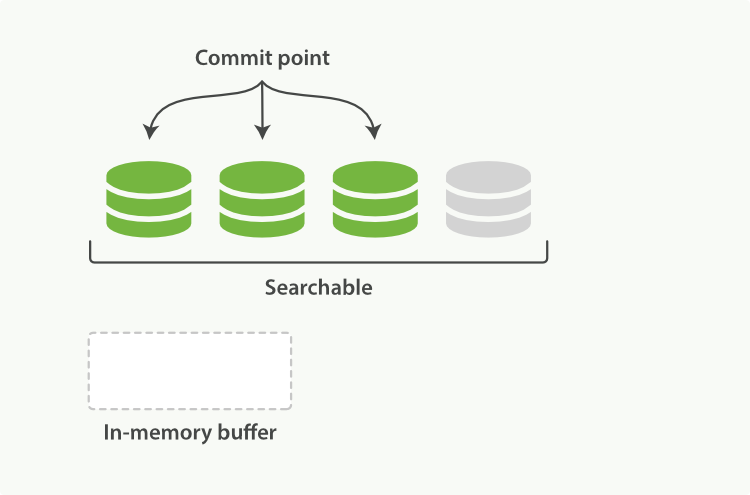
refresh动作会让内存中的数据写入到系统缓存中一个可被搜索但还没有commit到磁盘的段中。默认情况下索引段每秒钟refresh一次。以此达到索引的近实时建立。但这样就引入了另外一个问题,每个分段就是一个小的倒排索引,到时候可能会有很多个小倒排。因此就需要segment合并.且在flush前数据有丢失的可能性。
- **flush前如何持久化**
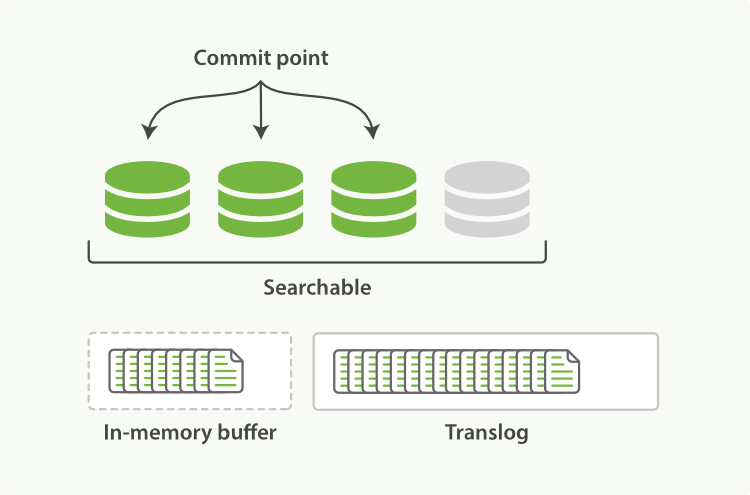
有的同学已经意识到,数据fsync到硬盘前可能会丢失。es通过Translog(事务日志)来解决这个问题。数据只要进入内存缓冲区,就会被写入到translog中,一直到这些数据fsync到disk为止。insert/update/delete等请求在写入到translog前不会被正确返回。
- **segment合并**
当segment越来越多的时候,segment需要被合并掉。
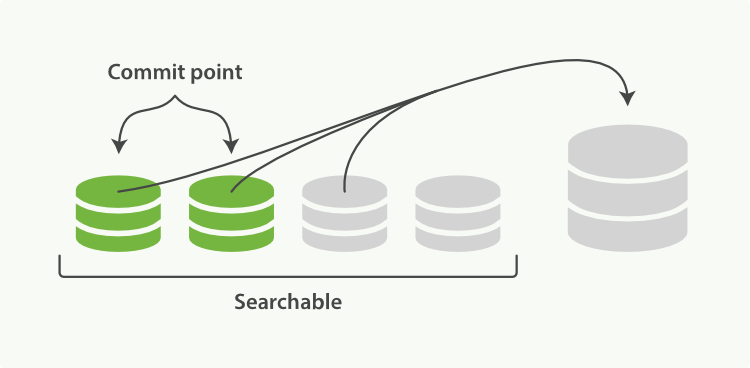

小的segment会被merge接口merge到大的分段中,等merge完毕,再删除掉已合并的分段。
## 并发冲突控制
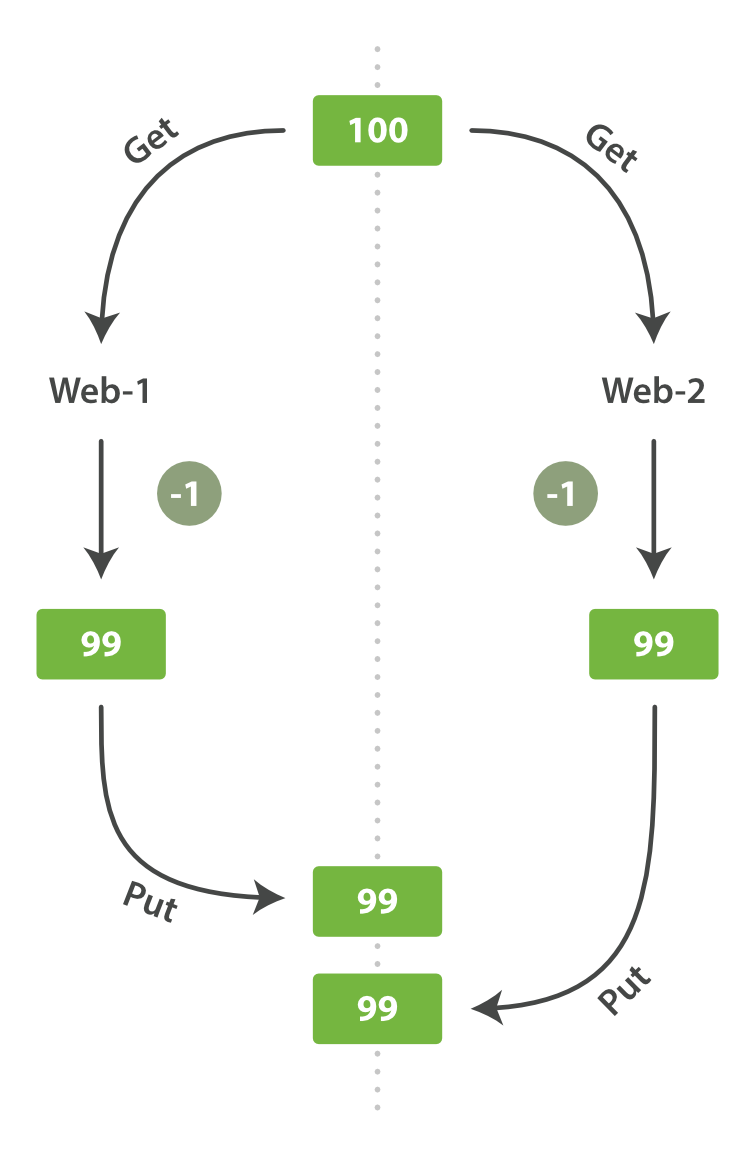
如上图所示,是个常见的事务场景,并发状况下更新同一行数据。
常见的数据库事务控制有两种方式。
- **悲观锁**
关系型数据库中常见的做法,排它锁进入锁住自己要的数据,禁止其他锁再来访问这条数据。
- **乐观锁**
elasticsearch采用乐观锁来控制这个事情。es假设这种事情是不会发生的,不阻塞用户行动,只有当请求失败了的时候,才会返回给用户执行失败。每行数据都有元数据字段_version,通过_version来达到版本号控制。
### 乐观锁并发控制
假设现在有数据如下,es中的每行数据都会带version,每次更新都会改变version版本。
1234567891011
{ _index: "fun_result", _type: "info", _id: "2235", _version: 1, _score: 1, _source: { name: "柳七", age: 20 } }
我们尝试发起修改数据请求,此时如果id为2235的数据version不为1,则es会返回错误码409操作冲突,以此达到乐观锁的目的。
12345
PUT /fun_result/info/2235?version=1 { "age": 20,"name": "王八"}